Creación de servicio para validar accesos en go
Este articulo es una continuación del articulo anterior «Arquitectura reactiva: Una solución enfocada en los datos«, por lo tanto podemos ir así al hueso del asunto, ¿cómo poder implementar esa solución enfocada en datos?, ¿qué es lo necesario para lograr tener el dominio sobre los datos? Primeramente debemos analizar el problema que enfrenta la empresa donde estamos, lo normal es que exista un artefacto de software que esté solucionando ya ese problema y sino, es quizás el primer paso que debemos dar. Crear una aplicación que solucione un problema.
Supongamos que existe una empresa con una necesidad muy simple: Cada vez que ciertos trabajadores con su carnet pasan por las puertas dentro de un edificio deslizando el identificador por un sensor el sistema enviará los datos del trabajador a un servicio web y esperará de vuelta una validación de si existe el permiso para entrar o no a cierto lugar. Para este caso común de negocio puede existir un servicio REST creado con Golang, esperando poder validar las peticiones. Aparte debe existir una base de datos (supongamos una base de datos relacional como mysql) donde esté guardada la información del usuario, también la información del sensor una tabla (que es la que nos interesa) donde están los acceso de cada usuario a ciertas entradas.
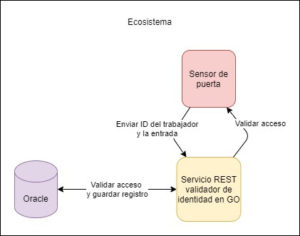
Diagrama #1
Veamos un poco del código de ese servicio validador para entenderlo quizás mejor, pero en general lo que hace es recibir el ID del carnet y del sensor principalmente (omitiendo temas de autenticación que no competen al artículo) con el cual busca en la base de datos y valida que el usuario tenga acceso.
|
type AccessInformation struct { Estructura que recibirá el servicio
func (c *AccessUseCase) ValidateAccess(access *entity.AccessInformation) error { return errors.New(«access denied») Validación de acceso con el repositorio
func (c *AccessUseCase) ValidateAccess(access *entity.AccessInformation) error { return errors.New(«access denied») func (c *AccessMysqlRepository) HasAccess(idPersonalInformation string, idSensor string) (bool, error) { Validación de acceso base de datos mysql |
Entonces este podría ser un servicio común con todo lo necesario para hacer funcionar este proceso correctamente. Pero alguien en la empresa se ha percatado que hay información útil en este proceso para la toma de decisiones. Y esa información es en qué lugar del edificio está cada trabajador y el tiempo que está en cada lugar históricamente (supongamos que esta información en realidad es útil de alguna manera). Entonces se ha decidido guardar en otra base de datos, quizás no relacional, el nombre del trabajador, su rol, cuál fue la última entrada por la cual pasó y la hora, aparte de un registro de cuánto tiempo ha estado en cada espacio.
En sí se trataría de que cada vez que el trabajador pasa por una entrada, luego de validar que este tiene acceso, se enviará un mensaje a otro artefacto con información como el id, nombre y rol del trabajador, un identificador de la entrada (ej. Sala de reuniones) y la fecha de acceso.
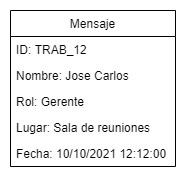
Diagrama #2
Con ese mensaje otro artefacto se encargará de buscar si ya existe el trabajador registrado. Si no existe lo creará, ingresando su información, entre la que estará el nombre del lugar donde está exactamente, agregando además el lugar a un registro con su fecha de entrada. Si el trabajador ya existe, este artefacto lo único que hará es actualizar el lugar donde está y la hora de acceso, pero además buscará el último registro para agregarle fecha de salida, además de agregar el tiempo que estuvo allí (la diferencia entre la entrada y la salida) agregando también el registro del nuevo lugar con su fecha de entrada.
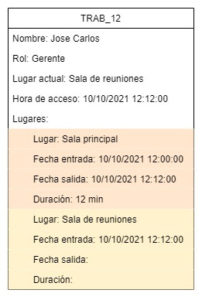
Diagrama #3
Entre estos dos artefactos o entre estas dos partes de la arquitectura debe haber un canal de comunicación y lo que es en sí mismo el corazón de cualquier arquitectura reactiva. Uno muy conocido, aparte de usado para estas soluciones, es kafka, un sistema de mensajes asíncronos. Esta será la manera de comunicarse de estos dos artefactos. Finalmente toda la arquitectura podría representarse así:
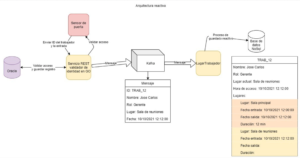
Diagrama #4
Creación de artefacto LugarTrabajador en Go
El artefacto que se encargará de guardar los datos tampoco será algo muy complejo, en general recibirá el mensaje de kafka (que más adelante se explicará cómo se implementa) y entonces se hace una consulta a esa base de datos nosql (mongoDb), donde se agregará o se actualizará los datos del trabajador y el lugar donde está. Para el tema de las fechas también, si ya existe el trabajador, se obtendrá la fecha de entrada del último lugar y se calculará la diferencia con la nueva fecha de entrada. Así suponiendo que no hay espacios muertos en el edificio se podrá saber cuánto tiempo ha estado en cada lugar.
|
func (c AccessRecordUseCase) CreateOrUpdateAccessRecord(record *entity.AccessRecord) { Creación o actualización de registros en general
func UpdateAccessRecord(record *entity.AccessRecord, document *entity.AccessRecordDocument) { Lógica de actualización de registro
func (c *AccessMongoDbRepository)GetAccessRecordDocument(idDocument string) (*entity.AccessRecordDocument, error) {
Código de procedimientos sobre Mongodb |
Configurar la conexión con kafka de los artefactos
Por último no se explicará en este artículo como desplegar un cluster de kafka ni cómo crear los tópicos, sin embargo ya existen muy buenas soluciones documentadas para hacerlo. Ya teniendo un cluster y el tópico creado, que en este caso se llamará: access-record, se puede enviar y recibir mensajes con go utilizando librerías como sarama, con lo cual se hará más fácil la conexión con kafka.
En el caso del producer, que sería nuestro artefacto de validación de acceso la conexión se haría de esta manera:
|
func NewAccessRecordKafkaProducer() *AccessRecordKafkaProducer { Código del kafka producer para el envío de mensajes
func (c *AccessUseCase) ValidateAccess(access *entity.AccessInformation) error { Implementación del envío de mensaje al validar |
Para el caso del consumer, que sería nuestro LugarTrabajador, la configuración para recibir mensaje por kafka sería de la siguiente manera:
|
func NewAccessRecordKafkaConsumer(usecase *application.AccessRecordUseCase) *AccessRecordKafkaConsumer { Código del kafka consumer para la lectura de mensajes |
Los datos: la puerta a mejores soluciones
Por lo tanto podríamos tener así, una arquitectura reactiva, una que haciendo uso de los datos de procesos ya digitalizados, pueda ir actualizando registros que estén en otro lugar de manera reactiva. Estos registros pueden ser usados por otra aplicación, en nuestro caso de ejemplo podría ser un visualizador para que algún jefe (sin muy buena cultura laboral) esté espiando lo que hacen sus trabajadores en cada momento, con gráficos incluidos y todo.
También la solución podría servir para que algún científico de datos pueda analizar qué roles tienden a estar en ciertos lugares del edificio con más frecuencia, lo que ayudaría a crear una mejor distribución de las oficinas. Pero podemos ir más allá y crear un modelo de machine learning que aprenda sobre las preferencias de los trabajadores por ciertos lugares del edificio y así poder asignar la mejor oficina para los nuevos ingresos según su rol. Hasta podíamos ingresar a la ecuación otros datos relacionados al trabajador, quizás para saber como ciertas características del mismo influyen en el tiempo que tarda en cada lugar del edificio.
Lo importante de una solución de esta magnitud es que esté enfocada en datos y es cuando la empresa logra controlar estos datos que tiene un mundo de posibilidades por delante, es en ese momento donde podrá mejorar su producto de manera exponencial. Los datos terminarán siendo la puerta, pero también el camino a las mejores soluciones.
¿Te animas a implementarlo? 💪

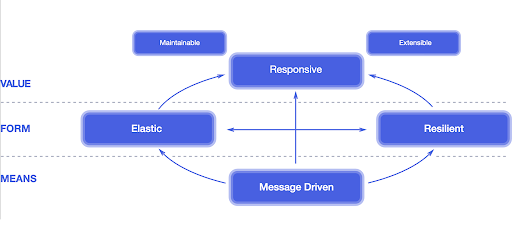 Sistemas reactivos: Responsivos, resilientes, elásticos y dirigidos por mensajes
Sistemas reactivos: Responsivos, resilientes, elásticos y dirigidos por mensajes